Bei der Verfolgung einer agilen Transformation können CEOs und CIOs eine gemeinsame Basis in fünf IT-Veränderungen finden, die es traditionellen Akteuren ermöglichen, mit digitalen Disruptoren zu konkurrieren.
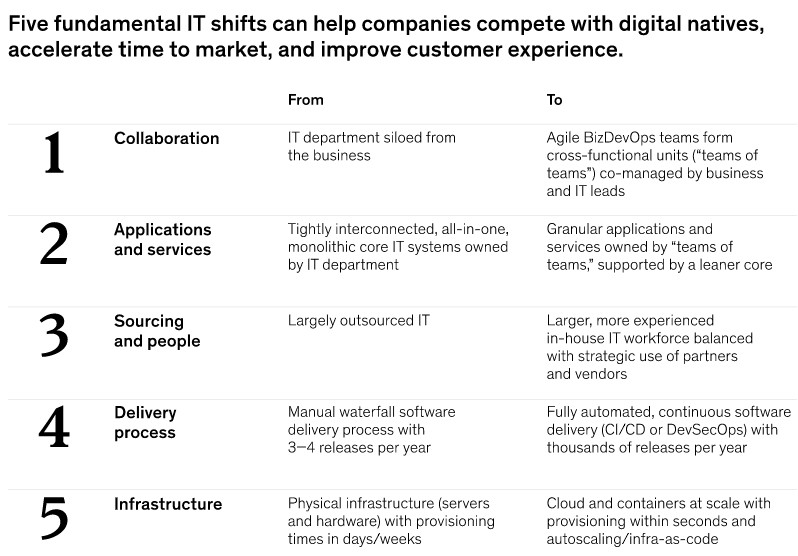
Um mit den Digital Natives konkurrieren zu können, sind fünf Veränderungen erforderlich: die Bildung wirklich funktionsübergreifender Teams mit gemeinsamer Führung von Business und IT, die Entkopplung von Kernsystemen, die Förderung von technischen Talenten, die Automatisierung der Softwarebereitstellung und die Einführung von Cloud-Infrastrukturen (siehe Abbildung 1). Jede dieser Veränderungen trägt durch spezifische Geschäftsergebnisse zur Agilität des Unternehmens bei und berücksichtigt die Ziele von CEO und CIO: Schnelligkeit der Bereitstellung, Kundenerfahrung, Qualität, Produktivität und Gesamtbetriebskosten.
5 Grundlegende IT Veränderungen
1: Zusammenarbeit: Von einer isolierten IT-Abteilung zu funktionsübergreifenden agilen Teams
Eine häufige Beschwerde von CEOs ist, dass die IT-Abteilung wie ein schwarzes Loch ist; sie sehen verzögerte Projekte und überzogene Budgets, und es kann schwierig sein, die IT-Produktivität zu messen. Auf der anderen Seite stellen CIOs fest, dass das Unternehmen oft eine endlose Reihe neuer Anforderungen stellt, die die IT-Abteilung nicht erfüllen kann, geschweige denn die entsprechenden technischen Schulden verwalten kann. In traditionellen Strukturen kann der Prozess der Definition und Abstimmung von Geschäfts- und IT-Anforderungen drei bis sechs Monate dauern, bevor die erste Codezeile überhaupt geschrieben wird.
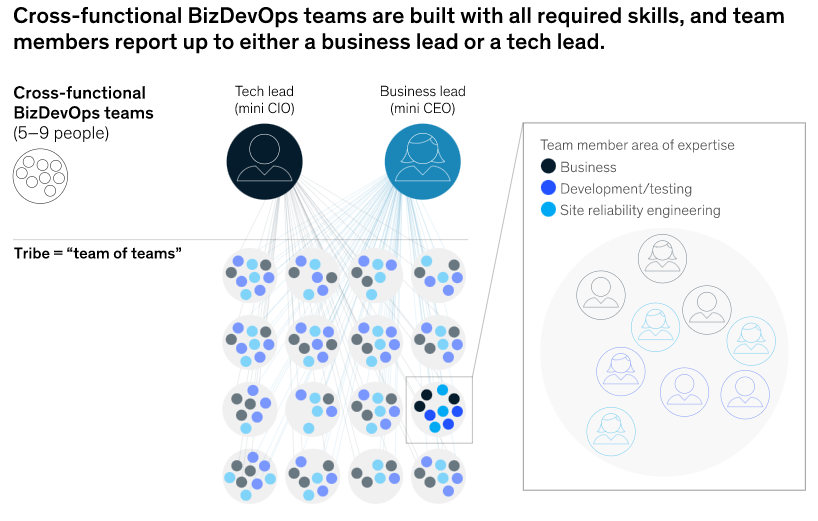 Die Überwindung dieser Dichotomie erfordert eine Verlagerung des Kooperationsmodells weg von einer isolierten IT-Abteilung hin zu funktionsübergreifenden Teams, die eine Mischung aus Fach- und IT-Experten enthalten. Diese Teams sind entscheidend für die Beschleunigung von Entwicklung, Markteinführung und Feedback-Integration, da sie Aufgaben mit möglichst wenigen Übergaben erfüllen. Den Kern dieses Modells bilden "BizDevOps"-Teams mit fünf bis neun Mitarbeitern, die über alle für die Erfüllung eines Auftrags erforderlichen Fähigkeiten verfügen: Business, Entwicklung und Tests sowie Site Reliability Engineering (Abbildung 2). Zu den Mitgliedern des Business-Teams gehören Produktverantwortliche, Produktexperten und Kundenerfahrungsexperten, die die Produktanforderungen auf der Grundlage der Kundenwünsche und des ROI festlegen. Die Ingenieure kümmern sich täglich um die Produktion von versandfähiger Software sowie um die Automatisierung, um die Freigabe und den zuverlässigen Betrieb in der Produktion zu gewährleisten. Durch die tägliche Interaktion kann das Team die Zeit für die Abstimmung der Anforderungen von Monaten auf Tage oder sogar Stunden verkürzen, was die Zeit bis zur Markteinführung und die Notwendigkeit, sich durch die Bürokratie zu kämpfen, radikal reduziert.
Die Überwindung dieser Dichotomie erfordert eine Verlagerung des Kooperationsmodells weg von einer isolierten IT-Abteilung hin zu funktionsübergreifenden Teams, die eine Mischung aus Fach- und IT-Experten enthalten. Diese Teams sind entscheidend für die Beschleunigung von Entwicklung, Markteinführung und Feedback-Integration, da sie Aufgaben mit möglichst wenigen Übergaben erfüllen. Den Kern dieses Modells bilden "BizDevOps"-Teams mit fünf bis neun Mitarbeitern, die über alle für die Erfüllung eines Auftrags erforderlichen Fähigkeiten verfügen: Business, Entwicklung und Tests sowie Site Reliability Engineering (Abbildung 2). Zu den Mitgliedern des Business-Teams gehören Produktverantwortliche, Produktexperten und Kundenerfahrungsexperten, die die Produktanforderungen auf der Grundlage der Kundenwünsche und des ROI festlegen. Die Ingenieure kümmern sich täglich um die Produktion von versandfähiger Software sowie um die Automatisierung, um die Freigabe und den zuverlässigen Betrieb in der Produktion zu gewährleisten. Durch die tägliche Interaktion kann das Team die Zeit für die Abstimmung der Anforderungen von Monaten auf Tage oder sogar Stunden verkürzen, was die Zeit bis zur Markteinführung und die Notwendigkeit, sich durch die Bürokratie zu kämpfen, radikal reduziert.
In der Praxis arbeiten diese BizDevOps-Teams parallel, um verschiedene Bereiche des Unternehmens zu unterstützen. Nehmen Sie die Beispiele mehrerer europäischer und asiatischer Banken und Telekommunikationsbetreiber, die eine große Anzahl dieser Teams eingerichtet haben, die sich in "Teams von Teams", den so genannten "Stämmen", aufteilen. In diesen Unternehmen bündeln Segmentstämme Produkte für bestimmte Geschäftssegmente und unterstützen kommerzielle Aktivitäten, während Produktstämme Produktmerkmale und produktspezifische Customer Journeys entwickeln. Um die Autonomie der Segment- und Produktstämme auszugleichen und die architektonische Konsistenz und IT-Kosteneffizienz zu wahren, richten Unternehmen auch Plattformstämme ein, die gemeinsame Dienste bereitstellen und wiederverwendbare Komponenten liefern, um die Arbeit der Ingenieure in den Geschäftsstämmen zu erleichtern. Beispiele hierfür sind Cybersecurity-as-a-Service-, Infrastructure-as-a-Service- und Data-as-a-Service-Stämme, die automatisierte Self-Service-Tools bereitstellen, sowie Kern-IT-Stämme, die komplexe Legacy-Systeme enthalten, die mehrere Stämme umfassen und (noch) nicht verteilt werden können.
In vielen Fällen übernehmen die Stämme das gesamte IT-Personal und die Verantwortung für die IT-Systeme, so dass die traditionelle IT-Abteilung nicht mehr existiert. Die Notwendigkeit - und die Verantwortung - des CIO bleibt jedoch bestehen, die technischen Schulden und die technische Qualität der Bereitstellung und Betriebszeit zu überwachen sowie IT-Talente anzuwerben und zu entwickeln. Um ein Gleichgewicht zu erreichen, können Unternehmen sicherstellen, dass jeder Stamm sowohl einen Geschäftsleiter ("Mini-CEO") als auch einen IT-Leiter ("Mini-CIO") hat. Häufig unterstehen die Leiter der Geschäftsbereiche dem Leiter des Geschäftsbereichs (in der Regel ein Mitglied des Vorstands, z. B. der Chief Commercial Officer), während die IT-Leiter dem CIO unterstellt sind, so dass der CIO ein gewisses Maß an Kontrolle und Rechenschaftspflicht hat.
2: Anwendungen und Dienstleistungen
Von einem monolithischen IT-Kern zu granularen Anwendungen und Diensten, die durch APIs isoliert sind und in den Händen von Teams liegen
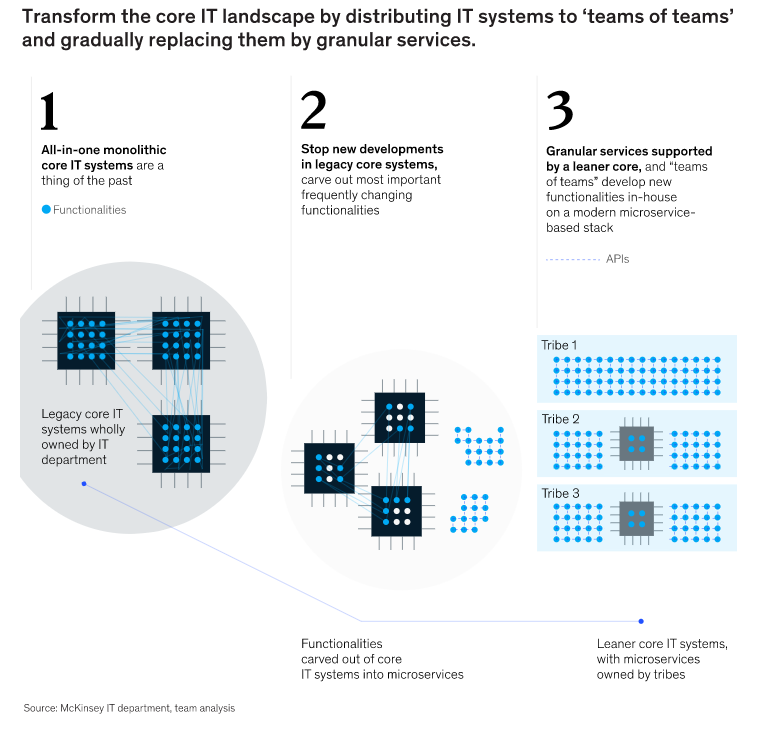 Monolithische "All-in-one"-IT-Systeme gehören der Vergangenheit an; die heutigen IT-Systeme müssen so granular sein, dass sie sich täglich unabhängig weiterentwickeln können. Traditionell waren Kernsysteme - wie z. B. Kernbankensysteme in Banken und Geschäftsunterstützungssysteme in der Telekommunikation - Dreh- und Angelpunkt für eine Vielzahl von Funktionen, die alle in einer Anwendung oder mehreren miteinander verbundenen monolithischen Anwendungen mit einer spaghettiartigen Anordnung von Verbindungen untergebracht waren. Diese Struktur hat zwar einige Vorteile in Bezug auf Skalierbarkeit und Rechengeschwindigkeit, aber die Änderung einer Funktion macht in der Regel Regressionstests für alle anderen Funktionen erforderlich, um sicherzustellen, dass nichts kaputt ist. Darüber hinaus waren viele der betroffenen Systeme aus den 1990er und 2000er Jahren für den stationären Einzelhandel oder sogar für Back-Office-Funktionen optimiert und ließen Mobil-, Web-, Partner-API- und andere digitale Kanäle außer Acht, die seither entstanden sind und die Komplexität erhöht haben. Bei einer Bank beispielsweise erforderte die Änderung eines Tarifs oder die Schaffung eines neuen Produkts Änderungen in bis zu 30 Systemen, was zu parallelen Entwicklungen in mehreren Abteilungen und wochenlangen Regressionstests führte, um Fehler in jedem dieser Systeme zu finden.
Monolithische "All-in-one"-IT-Systeme gehören der Vergangenheit an; die heutigen IT-Systeme müssen so granular sein, dass sie sich täglich unabhängig weiterentwickeln können. Traditionell waren Kernsysteme - wie z. B. Kernbankensysteme in Banken und Geschäftsunterstützungssysteme in der Telekommunikation - Dreh- und Angelpunkt für eine Vielzahl von Funktionen, die alle in einer Anwendung oder mehreren miteinander verbundenen monolithischen Anwendungen mit einer spaghettiartigen Anordnung von Verbindungen untergebracht waren. Diese Struktur hat zwar einige Vorteile in Bezug auf Skalierbarkeit und Rechengeschwindigkeit, aber die Änderung einer Funktion macht in der Regel Regressionstests für alle anderen Funktionen erforderlich, um sicherzustellen, dass nichts kaputt ist. Darüber hinaus waren viele der betroffenen Systeme aus den 1990er und 2000er Jahren für den stationären Einzelhandel oder sogar für Back-Office-Funktionen optimiert und ließen Mobil-, Web-, Partner-API- und andere digitale Kanäle außer Acht, die seither entstanden sind und die Komplexität erhöht haben. Bei einer Bank beispielsweise erforderte die Änderung eines Tarifs oder die Schaffung eines neuen Produkts Änderungen in bis zu 30 Systemen, was zu parallelen Entwicklungen in mehreren Abteilungen und wochenlangen Regressionstests führte, um Fehler in jedem dieser Systeme zu finden.
Der Ersatz solcher Kernsysteme war schon immer mit erheblichen Kosten verbunden - zwischen 50 und mehr als 500 Millionen Euro für ein mehrjähriges Programm. Aber das ist nicht unbedingt für alle Unternehmen der beste Weg in die Zukunft.
Stattdessen hat der Druck, großartige Kundenerlebnisse zu liefern und gleichzeitig Geld sinnvoll auszugeben, dazu geführt, dass eine Reihe von agilen Unternehmen das "Strangler-Muster" anwenden. Bei diesem Ansatz werden die Funktionen ausgewählt, die sich am häufigsten ändern (z. B. Kreditvergabeprozesse, Produktkataloge oder Tarifmodule, Scoring-Engines, Datenmodelle oder kundenorientierte Prozesse), die Verantwortung für diese Funktionen an Geschäfts- oder Plattformstämme übertragen und spezielle BizDevOps-Teams eingerichtet, die granulare und spezialisierte Dienste (häufig als Microservices bezeichnet) erstellen. Diese Dienste folgen dem Prinzip "ein Dienst - eine Funktion", wobei das herausgenommen wird, was nicht in die Altsysteme gehört, und ein schlankerer Kern übrig bleibt (Abbildung 3). Im Grunde genommen verkürzt dieser Ansatz die Zeit für die Entwicklung und Überarbeitung von Funktionalitäten und senkt so die Gesamtbetriebskosten.
Zwei Banken zeigen das Potenzial auf. Während die primären Funktionen des Bankensystems (wie z. B. ein Hauptbuch) im Kernsystem verbleiben sollten und werden, konnte eine Bank ihre monolithischen Kernbankensysteme um etwa 35 Prozent verschlanken, indem sie Nicht-Kernfunktionen in eine Microservice-Schicht oder spezialisierte Anwendungen (z. B. eine Preisgestaltungs-Engine oder einen Inkassodienst) ausgliederte und so häufige Änderungen an unabhängigen Microservices oder Modulen ermöglichte. Eine andere Bank wendete den Ansatz selektiv auf eine begrenzte Anzahl von Journeys an (einschließlich Onboarding und Cross-Selling), gliederte häufig wechselnde Funktionalitäten, die zur Unterstützung dieser Journeys erforderlich sind, aus Altsystemen in unabhängige Microservices aus und konnte die Markteinführungszeit für Funktionen, die diese Funktionalitäten betreffen, von Monaten auf Stunden verkürzen.
3: Beschaffung und Mitarbeiter: Vom IT-Outsourcing zur strategischen IT-Einstellung mit Partnern und Anbietern
Viele große, etablierte Unternehmen lagern einen großen Teil ihrer IT - wenn nicht sogar die gesamte IT - aus, zum Teil aus Kostengründen, zum Teil aber auch, weil es schwierig ist, die richtigen Talente von attraktiveren Disruptoren und Digital Natives abzuwerben. Es ist daher nicht verwunderlich, dass es immer mehr Anbieter gibt, die CIOs bei der Suche nach neuen Talenten unterstützen.
Unternehmen, die auf Unternehmensflexibilität setzen, können sich jedoch nicht zu sehr auf Anbieter und Partner stützen, die schlüsselfertige IT-Dienste anbieten. In dieser Welt ist das Paradigma, die IT vollständig an einen Anbieter auszulagern und Anträge für eine benötigte Änderung einzureichen, langsam und aufgrund der sich schnell ändernden Anforderungen nicht mehr geeignet. Der Wettbewerb mit den Digital Natives erfordert das tägliche Testen von Minimum Viable Products (MVPs) und lässt wenig Raum für Übergaben - sei es zwischen Abteilungen innerhalb eines Unternehmens oder mit externen Anbietern. Darüber hinaus ist eine kontinuierliche Erneuerung der Technologien erforderlich, da sich Entwicklungs-Frameworks, Bibliotheken und Muster jedes Jahr weiterentwickeln. Ein CEO war schockiert, als er erfuhr, dass es auf dem gesamten Arbeitsmarkt nur etwa 100 Personen gab, deren Lebensläufe darauf hindeuteten, dass sie in der Lage waren, mit dem alten, herstellerbasierten Kernsystem des Unternehmens zu arbeiten, während es Tausende gab, die mit Open-Source-Technologien arbeiten konnten. Diese Anforderungen lassen sich viel leichter mit internen Talenten erfüllen, die in Kernteams eingebettet sind.
Um ihren Talentbedarf zu decken, hat eine europäische Bank ihre IT-Belegschaft komplett umgestaltet, indem sie die Ingenieure identifizierte, die tatsächlich programmieren, und den Anteil der Programmierer radikal von etwa 10 % auf 80 % erhöhte. Außerdem wurden alle Ingenieure auf einer Fähigkeitsskala (von Anfängern bis zu Experten, auf einer Skala von 1 bis 5) eingeordnet und eine rautenförmige Zusammensetzung der Talente angestrebt. Diese Konfiguration erhöhte den Anteil der IT-Mitarbeiter, die als Experten oder fortgeschrittene Ingenieure (in der Mitte der Raute) eingestuft werden und die exponentiell produktiver, aber nicht exponentiell teurer sind als weniger erfahrene Ingenieure. Das Ergebnis war eine vollständige Erneuerung des IT-Personals von etwa 2.000 Vollzeitäquivalenten (FTE), wobei die erfahrenen Ingenieure 80 Prozent der Belegschaft ausmachten und Kosteneinsparungen von 40 Prozent erzielten. Ein internationales Telekommunikationsunternehmen stellte Hunderte von Ingenieuren ein, hauptsächlich durch Insourcing, aber auch durch das Angebot von Zeit- und Materialverträgen zwischen einzelnen Ingenieuren oder sogar Lieferanten. Eine andere internationale Bank stellte mehrere Tausend Ingenieure ein, baute ein Talent-Ökosystem mit Anbietern und Cloud-Providern auf, um jüngere und seltenere Talente anzuziehen, und startete Umschulungsinitiativen, um mehr als 6.000 Entwickler und Architekten weiterzubilden.
Die Anbieter ihrerseits passen sich ebenfalls an und finden neue Wege der Zusammenarbeit. Einerseits bieten sie mehr API-zugängliche Software-as-a-Service (SaaS)- und Plattform-as-a-Service (PaaS)-Lösungen an, die bestimmte schlüsselfertige Funktionen bieten, die ohne weitere Vorkenntnisse genutzt werden können. Andererseits stellen Unternehmen auf Anfrage hochspezialisierte und erfahrene Talente zur Verfügung - z. B. im Rahmen strategischer Partnerschaften - und bieten damit Alternativen zu den typischen Anbieterpaketen, die auch unerfahrene Mitarbeiter umfassen.
4: Lieferprozess: Vom Wasserfallprozess zur kontinuierlichen Lieferung
 Die Geschwindigkeit der Bereitstellung ist ein ständiger Streitpunkt zwischen CEOs und CIOs. CEOs sind oft frustriert über die Zeit, die ein traditionelles Unternehmen benötigt, um alle Schritte der Wasserfall-Bereitstellung zu durchlaufen, während CIOs davor warnen, dass eine schnellere Bereitstellung zu Produktionsausfällen führen kann. Während ein durchschnittliches Unternehmen in der Lage ist, drei bis vier größere Funktions-Upgrades pro Jahr zu veröffentlichen, und schnellere Unternehmen zehn bis 12 erreichen, können digital-native Unternehmen wie Amazon, Google und die meisten digitalen Start-ups praktisch jederzeit nach Bedarf veröffentlichen - wöchentlich, täglich oder stündlich. Dies ermöglicht es Digital Natives, verschiedene Versionen der gleichen Funktionalität mit verschiedenen Kunden zu testen, MVPs jederzeit zu testen, Kundenfeedback schnell einzubeziehen und das Unternehmen kontinuierlich weiterzuentwickeln, wodurch ein echtes Maß an Agilität erreicht wird. Mehrere traditionelle Banken und Telekommunikationsunternehmen in Europa und Asien haben diesen Weg eingeschlagen und erreichen bis zu 20.000 Releases pro Quartal, selbst bei Back-End-Systemen.
Die Geschwindigkeit der Bereitstellung ist ein ständiger Streitpunkt zwischen CEOs und CIOs. CEOs sind oft frustriert über die Zeit, die ein traditionelles Unternehmen benötigt, um alle Schritte der Wasserfall-Bereitstellung zu durchlaufen, während CIOs davor warnen, dass eine schnellere Bereitstellung zu Produktionsausfällen führen kann. Während ein durchschnittliches Unternehmen in der Lage ist, drei bis vier größere Funktions-Upgrades pro Jahr zu veröffentlichen, und schnellere Unternehmen zehn bis 12 erreichen, können digital-native Unternehmen wie Amazon, Google und die meisten digitalen Start-ups praktisch jederzeit nach Bedarf veröffentlichen - wöchentlich, täglich oder stündlich. Dies ermöglicht es Digital Natives, verschiedene Versionen der gleichen Funktionalität mit verschiedenen Kunden zu testen, MVPs jederzeit zu testen, Kundenfeedback schnell einzubeziehen und das Unternehmen kontinuierlich weiterzuentwickeln, wodurch ein echtes Maß an Agilität erreicht wird. Mehrere traditionelle Banken und Telekommunikationsunternehmen in Europa und Asien haben diesen Weg eingeschlagen und erreichen bis zu 20.000 Releases pro Quartal, selbst bei Back-End-Systemen.
Die Beschleunigung der Bereitstellung muss nicht auf Kosten der Qualität gehen. Wenn kompetente Ingenieure an autonomen Microservices arbeiten, können sie die wahre Stärke von Continuous Integration und Continuous Delivery (CI/CD) ausspielen. Das Geheimnis dieses Wandels liegt in der Automatisierung von Aufgaben, um häufige inkrementelle Releases zu ermöglichen (siehe Abbildung 4). Alle Phasen der Bereitstellung eines Dienstes, von der Kodierung über das Testen bis hin zur Bereitstellung, werden automatisiert, einschließlich der Sicherheitstests in den DevOps-Pipelines - was gemeinhin als DevSecOps bezeichnet wird. Eine fortschrittliche internationale Bank ging noch einen Schritt weiter und schuf eine interne Plattform als Service für Entwickler. Jeder Entwickler konnte über ein globales Portal auf Vorlagen von Diensten zugreifen und mit einem Mausklick automatisch die erforderliche Infrastruktur, CI/CD-Pipeline, Sicherheitstools und API-Definition aufrufen. Dies ermöglichte es den Entwicklern, sich auf die Programmierung der eigentlichen Geschäftsfunktionen zu konzentrieren, anstatt Zeit mit der Einrichtung von Pipelines und Infrastrukturkonfigurationen zu verschwenden.
Da nicht alle Systeme vom ersten Tag an einsatzbereit sein werden, müssen einige Unternehmen einen differenzierten Ansatz verfolgen, indem sie API-fähige Systeme jederzeit freigeben und Release-Züge für Systeme einführen, die Regressionstests erfordern, und gleichzeitig in deren Automatisierung investieren. Diese Automatisierung und Beschleunigung des Bereitstellungsprozesses wird in der Regel von speziellen Delivery-Platform-as-a-Service-Einheiten vorangetrieben, die alle "Teams von Teams" in einem Unternehmen bei der Übernahme von Engineering-Praktiken unterstützen, indem sie Tools wie CI/CD-Pipelines einrichten und pflegen.
5: Infrastruktur: Von physischer Infrastruktur zu Cloud, Containern und Infrastruktur als Code
Schließlich wäre keine Diskussion über den Einsatz von Technologie in einem agilen Unternehmen vollständig, ohne die Cloud-Infrastruktur zu erwähnen - öffentlich, privat oder hybrid. Ähnlich wie bei der Automatisierung ermöglicht die Cloud-Infrastruktur den Unternehmen, Rechen- und Speicherkapazitäten nach Bedarf abzurufen, bürokratische Verfahren zu überspringen und eine Umgebung in Sekundenschnelle einzurichten, anstatt wochenlang zu warten. Wie unsere früheren Untersuchungen gezeigt haben, planen fast 80 Prozent der Unternehmen bereits, in den nächsten drei Jahren mindestens 10 Prozent ihrer Arbeitslasten in die öffentliche Cloud zu verlagern.
Mehrere Banken und Telekommunikationsunternehmen in Europa und Russland haben ihre Produktions- und Testlasten zu Cloud-Anbietern verlagert. So nutzt beispielsweise eine westeuropäische Bank die flexible Kapazität der Cloud für das Hosting von Testumgebungen, eine osteuropäische Bank nutzt sie für das Hosting von Test- und Produktionsumgebungen für ausgewählte Anwendungen und Customer Journeys in Übereinstimmung mit den Bundesgesetzen, und eine europäische Telekommunikationsgesellschaft hat ihre gesamte API-Schicht in der Cloud. Die meisten fortschrittlichen Unternehmen nutzen das Infrastructure-as-Code-Konzept, um Kapazitäten über eine API zu beziehen und zusätzliche Umgebungen direkt von der Software anzufordern, statt über physische Hardwarekonfigurationen. In der Regel ist ein IT-Infrastruktur-Stamm dafür verantwortlich.
Wenn sie zusammen mit CI/CD eingesetzt wird, hat sich gezeigt, dass die Cloud-Infrastruktur mehrere wichtige IT-Kennzahlen radikal verbessern kann - vor allem durch die Beseitigung von Wartezeiten und Nacharbeiten sowie von Bedarfsprognosen. So konnten Unternehmen beispielsweise die Zykluszeit durch die Implementierung standardisierter Prozesse und Automatisierung verkürzen und Softwarebereitstellungen und -tests beschleunigen. Einige Teams, die früher zwei Tage pro Sprint für Regressionstests benötigten, können dieselbe Aufgabe jetzt in nur zwei Stunden erledigen. Neben der Produktivitätssteigerung können Unternehmen auch die IT-Overhead-Kosten erheblich senken, indem sie die Nutzung von IT-Ressourcen optimieren und die Flexibilität der IT bei der Erfüllung von Geschäftsanforderungen insgesamt verbessern. In der Tat bieten Cloud-Anbieter in zunehmendem Maße weitaus anspruchsvollere Lösungen als einfache Rechen- und Speicherdienste an, wie z. B. Big Data- und Machine-Learning-Dienste. Es hat sich gezeigt, dass Cloud-Infrastrukturen und CI/CD auch die Markteinführung beschleunigen und die Servicequalität durch die "Selbstheilung" von Standardlösungen verbessern - beispielsweise durch die automatische Zuweisung von mehr Speicherplatz für eine Datenbank, die sich ihrer Kapazität nähert.

 Einblicke
Einblicke